Power Query: Falsche Datentypen? Drei Tipps, die das verhindern
04.08.2025
Es sollte mal wieder schnell gehen und dabei bleib das Festlegen der Datentypen auf der Strecke. Doch spätestens beim nächsten Datenimport rächt sich das. Denn unsachgemäß eingestellte oder bei erneuten Importen nicht überprüfte Datentypen erhöhen das Risiko von Fehlern und Datenverfälschungen. Hier zwei typische Beispiele:
1) In der Abfrage wurden die Datentypen sauber definiert: der Spalte mit der Mengenangabe wurde Ganze Zahl zugewiesen. Beim Import der nächsten Monatsdaten enthält die Spalte mit den Mengenangaben plötzlich Werte mit Dezimalstellen. Die werden automatisch abgeschnitten, da Ganze Zahl eingestellt ist. Eine Verfälschung der Daten ist die Folge.
2) Für die Spalte Menge wurde Ganze Zahl festgelegt, aber beim nächsten Import stehen in der Spalte Menge solche Einträge wie 1 Kiste oder 1 Karton. Das hat Fehler zur Folge, die das Aktualisieren der Daten behindern.
Dies zeigt, dass die Kontrolle der Datentypen in zwei Schritten erfolgen muss: 1) beim Aufbau der Abfrage und 2) beim Import neuer Daten. WIE das geht, zeige ich in diesem Beitrag.
![Datentyp beim Erstellen der Analyse gezielt einstellen [1] und beim Update kontrollieren [2]](https://www.huegemann-informatik.de/wp-content/uploads/2025/08/1_FalscheDatentypen.png)
Datentyp beim Erstellen der Analyse gezielt einstellen [1] und beim Update kontrollieren [2]
Wichtige Voreinstellung: Den Automatismus von Power Query abstellen
Beim Einlesen von Daten versucht Power Query, den effizientesten Datentyp einzustellen – egal, ob in Power BI Desktop oder Excel.
- Ist die Quelle eine Datenbank, dann sind die Datentypen schon vorgegeben und alles sollte problemlos funktionieren.
- Anders ist es mit unstrukturierten Daten wie XLSX, CSV oder TXT. Standardmäßig ist in Power Query die automatische Datentyperkennung für unstrukturierte Quellen aktiviert. Die Datentypen müssen daher auf jeden Fall kontrolliert und gegebenenfalls geändert werden.
Der richtige Datentyp führt nicht nur zu einer besseren Performance, sondern ist auch entscheidend für DAX-Berechnungen. Wird beispielsweise der Datentyp Dezimalzahl für eine Spalte gewählt, die nur ganze Zahlen beinhaltet, ist das nicht sehr effizient, da mehr Speicherplatz benötigt wird.
TIPP: Die automatische Typerkennung im Power Query-Editor lässt sich über Datei > Optionen und Einstellungen > Optionen ausschalten.

Die automatische Datentyperkennung kann in den Power Query-Optionen ausgeschaltet werden
Schritt 1: »Data Profiling« nutzen, um den optimalen Datentyp einzustellen
Woher weiß ich, welcher Datentyp der richtige ist? Hier hilft das »Data Profiling«.
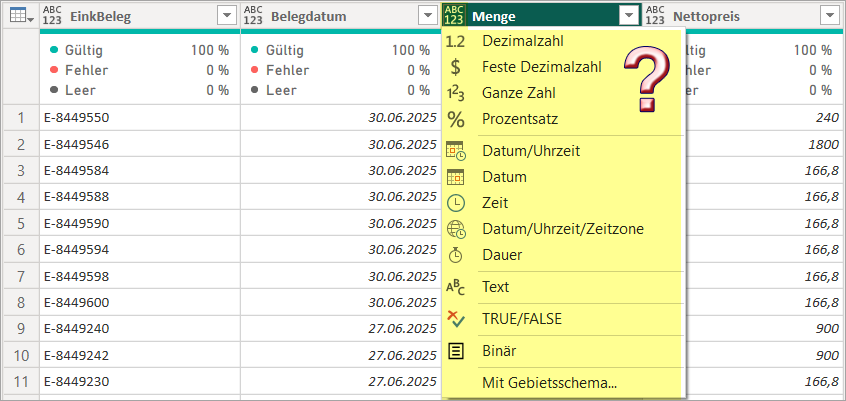
Den Datentyp Any (Symbol: ABC123) durch einen optimalen Datentyp ersetzen
So gehe ich vor, um den optimalen Datentyp – hier für die Zahlenspalte Menge – zu finden:
- Ich wähle zunächst den größten Datentyp für Zahl aus, nämlich Dezimalzahl.
- Um sicherzugehen, dass diese Spalte auch keine anderen Daten außer Zahlen enthält, prüfe ich zunächst die Spaltenqualität über Ansicht [1] und Häkchen bei Spaltenqualität [2].
- Da die Spaltenqualität standardmäßig nur auf den ersten 1.000 Zeilen geprüft wird [3], stelle ich Spaltenprofilerkennung basierend auf dem gesamten Dataset [4] ein.
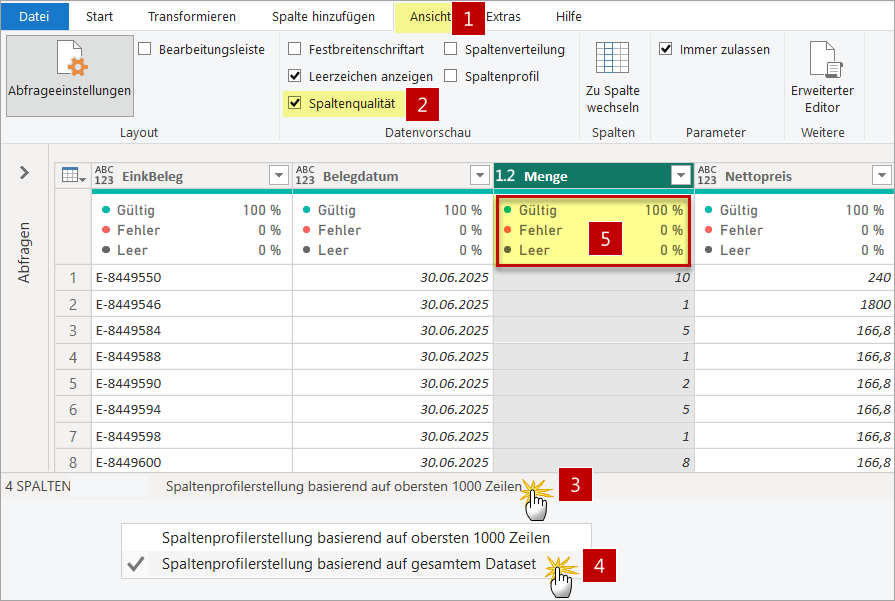
Nach dem Einstellen des Datentyps zunächst die Daten auf Gültigkeit prüfen mit Hilfe der Ansicht Spaltenqualität
- Zeigen sich oben in der Spaltenprofilanzeige [5] keine Fehler, kann es weitergehen mit dem Inspizieren des Zahlenbereichs. Ansonsten merze ich zunächst die Fehler in meiner Quelle aus.
- Um die Zahlen besser inspizieren zu können, wähle ich unter Ansicht [1] > Spaltenprofil [2] aus. Damit der komplette Bestand geprüft wird, stelle ich wieder Spaltenprofilerkennung basierend auf dem gesamten Dataset [3] ein.
- Jetzt kann ich mir mit Hilfe der Spaltenstatistik [4] beispielsweise Min- und Max-Werte ansehen und eventuell überschrittene Grenzwerte erkennen. Die Wertverteilung [5] gibt Auskunft über die verschiedenen vorkommenden Werte. Hier sehe ich, dass nur ganze Zahlen bei den Mengenangaben verwendet werden.
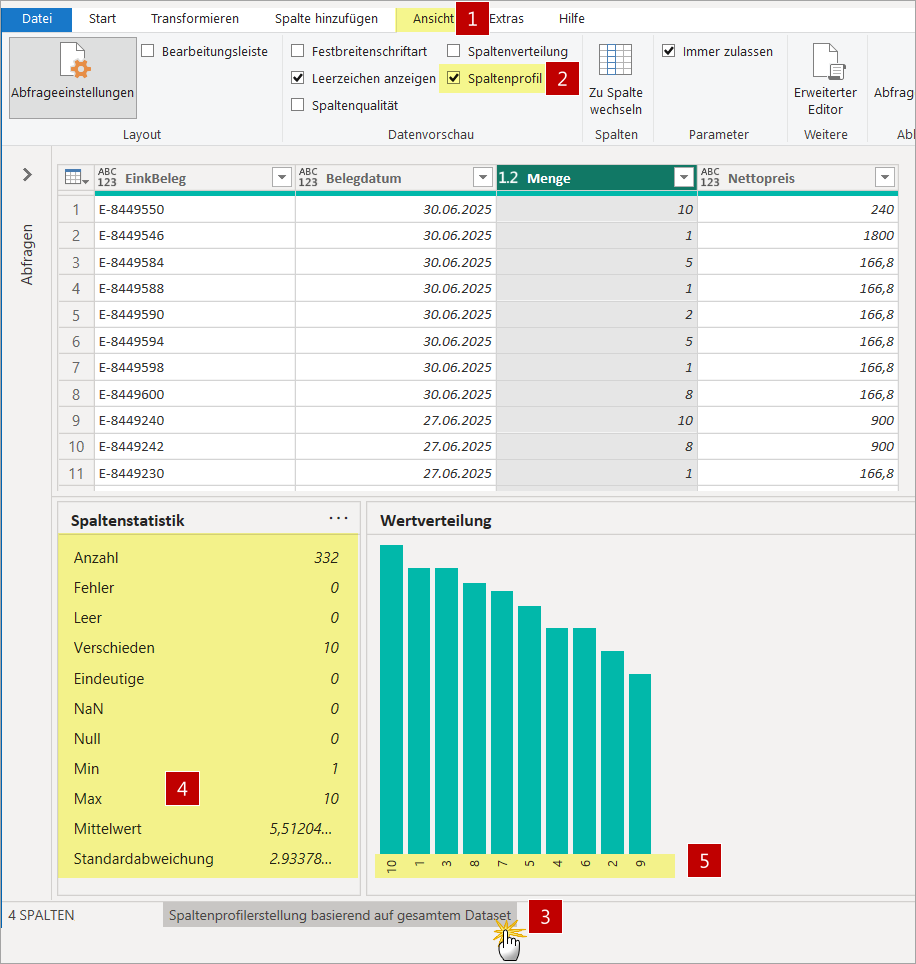
Mit Hilfe der Ansicht Spaltenprofil können überschrittene Grenzwerte erkannt und die vorhandenen Werte eingesehen werden
- Bin ich mir dann sicher, dass der Zahlentyp Ganze Zahl ausreicht, ersetze ich den Datentyp Dezimalzahl für die Menge Spalte durch den Datentyp Ganze Zahl.
Schritt 2: Fehler und unbemerkte Datenverfälschungen beim Import weiterer Daten vermeiden
Kommen neue Daten hinzu, ist nicht sicher, ob der eingestellte Datentyp – beispielsweise Ganze Zahl – noch passt. Daher muss zeitgleich mit dem Einlesen neuer Daten eine Prüfung mitlaufen, die anzeigt, ob unerwartete Daten dabei sind, bevor später die Analyse beginnt. So gehe ich vor:
- Ich lese die Datenquelle erneut ein, ohne Datentypänderungen vorzunehmen und benenne sie in diesem Beispiel mit Mengenangaben_Pruefen.
- Nun markiere ich alle Spalten, die für das Identifizieren fehlerbehafteter Datensätze nötig sind, hier die Spalte EinkBeleg und die Spalte Menge. Per Rechtsklick im markierten Spaltenkopf wähle ich Andere Spalten entfernen.
- Über Spalte hinzufügen > Benutzerdefinierte Spalte erstelle ich eine Formel, die mir in diesem Fall ausgibt, ob es sich um eine Dezimalzahl, eine Ganze Zahl, einen Text oder einen anderen Datentyp handelt.
- Die Prüfung auf Dezimalzahl nehme ich vor, indem ich von der Menge die auf 0 Nachkommastellen gerundete Zahl abziehe. Damit die Berechnungen im Fall von Text oder einem anderen Datentyp nicht zu einem Fehler führen, prüfe ich vor der Berechnung mit »is number«, ob Menge eine Zahl ist.
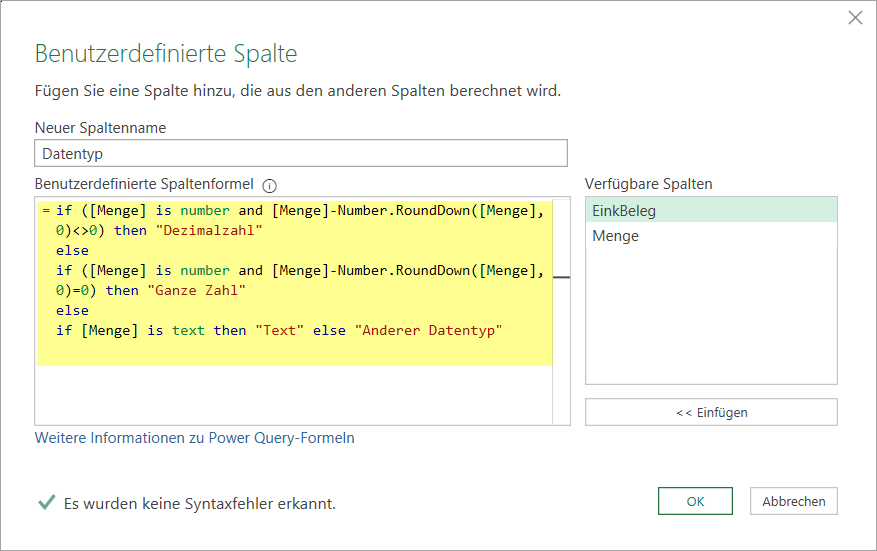
Per Formel wird auf verschiedene Datentypen geprüft, die eventuell von Ganze Zahl abweichen
- Das Ergebnis dieser Abfrage sind drei Spalten.
- Um alle Einträge zu sehen, die nicht meinem eingestellten Datentyp Ganze Zahl entsprechen, filtere [1] ich die neue Spalte Datentyp per Textfilter [2] auf alle Einträge, die nicht Ganze Zahl sind [3] [4].
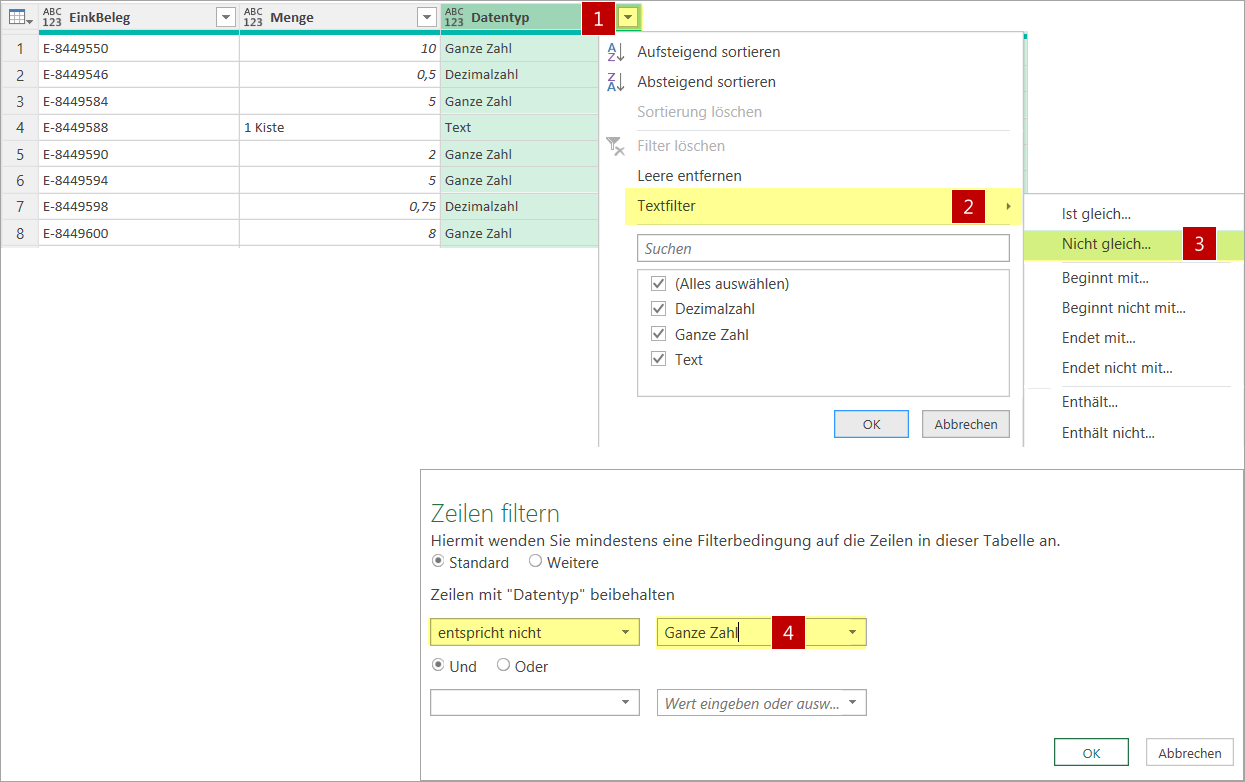
Die neu erstellte Prüfspalte auf alle Einträge ungleich Ganze Zahl filtern
- Das Ergebnis der Abfrage kann ich mir in Excel als Tabelle laden.
- In Power BI Desktop erstelle ich eine Prüfseite mit Tabelle als Visual. So habe ich stets die Ausreißer in dieser Spalte im Blick und kann sie korrigieren, bevor sie die Analyse verfälschen.
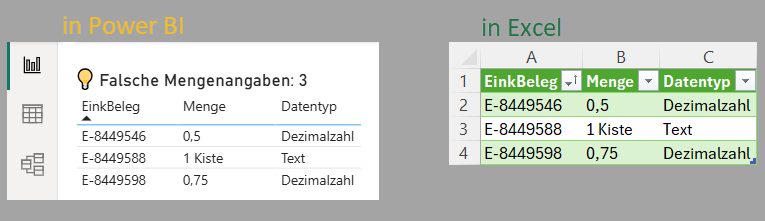
Kontrollabfragen, die Ausreißer in den Mengenangaben aufdecken
Fazit
Das bewusste Setzen, Überprüfen und regelmäßige Kontrollieren der Datentypen in Power Query ist essenziell, um Fehler beim Aufbereiten und Analysieren der Daten zu vermeiden. Data Profiling und eine Kontrollabfrage – wie beispielhaft oben gezeigt – helfen, potenzielle Fehlerquellen frühzeitig zu erkennen und auszuschalten.
Ähnliche Beiträge
-
Power Query: Spaltenwerte flexibel und effizient verändern
Soll in Power Query der Inhalt einer Spalte verändert werden, sind dafür auf der Registerkarte Transformieren verschiedene Befehle verfügbar. Allerdings gibt es dort keine Option, die unterschiedliche Werte einer vorhandenen...
-
Power Query: Ausgeblendete Arbeitsblätter auslesen? So geht’s doch!
Kürzlich erhielt ich den Hilferuf einer Anwenderin, weil sie in Excel mit Power Query nicht auf die Daten in einer anderen Arbeitsmappe zugreifen konnte. Sie wurden im Navigator nicht angezeigt....
-
Power Query: Spalten entfernen ja, aber bitte richtig
Kürzlich hatte ich im Kurs eine spannende Diskussion zum Entfernen von Spalten. Die Frage war: Was tun, wenn sich nach dem Entfernen mehrerer Spalten herausstellt, dass es eine zu viel...




